

This summertime Kaspersky specialists participated in the Machine Learning Security Evasion Competition ( MLSEC ) —– a series of trials evaluating entrants’ capability to assault and develop artificial intelligence designs. The occasion is consisted of 2 primary obstacles —– one for enemies, and the other for protectors. The aggressor difficulty was divided into 2 tracks —– Anti-Malware Evasion and Anti-Phishing Evasion. Despite the fact that in our regular work we tend to handle ML-based security innovations, this time we chose to enter the assailants’ shoes and picked the offending tracks. Our Anti-Malware Evasion group included 2 information researchers —– Alexey Antonov and Alexey Kogtenkov —– and security specialist Maxim Golovkin. In the Anti-Phishing Evasion group there were 2 more information researchers —– Vladislav Tushkanov and Dmitry Evdokimov.
.MLSEC.IO Phishing Track.
In the phishing track the job was to customize 10 (artificial) phishing samples (i.e. HTML pages) to encourage 7 phishing detection designs that they were benign. If it returned a possibility of less than 0.1 for each sample, a design was bypassed. There was a catch: after the adjustments the samples had to look the very same as prior to (or to be precise, render screenshots were to have the exact same hashes for both the initial and customized html file). Designs were readily available by means of an API, suggesting that the setting was black-box. To win we needed to trick as numerous designs as possible for each sample utilizing the least possible variety of API inquiries.
.What we did.
At initially, we considered trying a traditional design duplication attack (see AML.T0005 of MITRE ATLAS), however after we went into the competitors we observed that the leader currently got the greatest possible rating utilizing simply 343 API calls (with one complete upload costing 70 calls). This sort of attack would include sending a great deal of phishing/non-phishing pages to recover design outputs and training “shadow” designs of our own, which we would then try to bypass offline. We did not have the API inquiry budget plan for that, which most likely made the setting a bit more reasonable. We, for that reason, needed to trust our domain competence and pure opportunity. We began by sending numerous tidy (benign) websites —– such as Wikipedia’s —– to inspect what possibilities the designs would return. While the very first 3 designs were rather pleased with them, the staying 4 regularly produced possibilities method above 0.1. From the API action speed we observed that the designs may be consuming raw HTML with no sort of web browser making.
.Cluttering the page with unnoticeable text.
We made up a basic script to examine render hashes and attempted our very first option —– including a big concealed piece of Wikipedia text to the phishing sample, repairing void HTML and using minification. This worked, however just for the very first 3 designs. We questioned whether a few of the designs might be overfitting the supplied samples. As we went along, we found out that the last 3 designs typically had the very same ratings, so we just checked our samples on the previous design (most likely the most delicate one) to conserve API calls.
.Obfuscation by means of byte shift.
When dealing with phishing detection, we, like Rutger Hauer in Blade Runner , had actually seen things. Phishing payloads concealed in Morse code. Phishing pages consisting practically completely of screenshots in base64. Real page text secured with ROT13. Making use of this domain understanding, we designed our very first obfuscation plan:
.Develop a little phony “individual blog site” page.Take the real phishing page, move all the signs by n and shop as a string.On page load, move the signs back and document.write the outcome back to the page. This turned out to be a bad concept —– not just did the moving procedure develop all kinds of getting away problems, the last 3 designs still sounded alarms on our samples. We included popular header tags, such as <>, which in some way resulted in poorer outcomes on the very first 3 designs. It seemed like the last 3 designs were dissatisfied about the a great deal of HTML tags or, most likely, the high-entropy payload string.Obfuscation by means of byte integer encoding.
We then attempted another type of obfuscation. Rather of moving, we encoded each byte as an integer number and put the numbers into unnoticeable <> tags. This tricked the very first 4 designs, however not the last 3. The outcomes were much better. We questioned whether the last 3 designs responded highly to the obfuscator code. Possibly they didn’t like document.write? We sent an empty page with the obfuscator present and discovered that the likelihoods were rather low —– from 0.074 for the very first 4 designs to 0.19 for the staying 3 —– suggesting the phishy JavaScript was not what the designs were taking a look at.
.Less tags, more text.
We assumed that the designs in some way considered character circulation. Considering their possible hostility to HTML tags, we utilized a huge piece of raw text —– an excerpt from the Bible. We included the appropriate <> to the header and concealed pieces of numericized bytes amongst the verses, like this:
20:18 And he stated, Whether [101 49 99 114 117 119 89 79 108 80 78 90 65 83 83 47 56 122 74 74 57.69 104 108 85 67 105 72 106 108] they be come out for peace, take them alive;.or whether they [70 50 43 97 107 121 71 68 48 47 104 105 83 86 86 108 107 106 107 48 114 111 49.114 78 83 49 85 118 75] be come out for war, take them alive.
This worked! 9 pages out of 10 bypassed all 7 designs, while the 03.html sample was turned down as too big (the optimum size was experimentally identified to be 10 MB). All the likelihoods were the exact same:
.00.01.02.03.04.05.06.0.02.0.02.0.02.0.02.0.084.0.087.0.087.
By that time, we still had about 50 API calls.
.Back to base (64 ).
This obfuscation plan was extremely ineffective, each byte a minimum of quadrupled. 03.html was a beast of a page, weighing 4 MB due to a couple of high-res base64 encoded images. We went into the source code and discovered that a few of them were duplicated, so we sculpted them out. The page lost weight to 1.7 MB. Sadly, to make the obfuscated page less than 10 MB, we were required to significantly increase the numbers-to-text ratio. The last 3 designs sounded alarms, most likely due to the fact that they were suspicious of the uncommon character count circulation. We discovered that if we altered the separator from an area to , the sample bypassed them, and the designs did at least some kind of processing line by line. In addition to mishandling, the pages filled really gradually. Sluggish in reality that the grading system returned a screenshot equality check failure for 03.html with byte-to-integer obfuscation. We watched out for utilizing base64 initially, as it was frequently utilized in the initial samples, however in the passing away hours of the competitors, we chose to provide it a shot and positioned base64 pieces amongst the cape text:
PGhlYWQ+ PG1ldGEgY2hhcnNldD11dGYtOD48bWV0.1:2 And the earth lacked kind, and space; and darkness was upon.YSBjb250ZW50PSJ3aWR0aD1kZXZpY2Utd2lkdGgs.the face of the deep. And the Spirit of God moved upon the face of the.IGluaXRpYWwtc2NhbGU9MS4wIiBuYW1lPXZpZXdw.waters.b3J0PjxtZXRhIGNvbnRlbnQ9IlNpdGUgRGVzaWdu
It worked! The page packing time likewise reduced dramatically, and we had the ability to lastly get the complete rating for 03.html with the following design outputs:
.00.01.02.03.04.05.06.0.017.0.017.0.017.0.017.0.072.0.076.0.076.
Thus, we had the ability to deceive the designs and took top place in the anti-phishing track.
.MLSEC.IO Anti-Malware Track.
The anti-malware track included 2 parts. The protective part had to do with developing anti-malware designs resistant to adversarial attacks. Keep in mind that these designs need to fulfill particular quality requirements relating to FPR/TPR on some concealed dataset, so it is difficult to produce a design that would merely spot all files. The job was to supply 6 designs for assaulting.
The adversarial part had to do with customizing 50 destructive files in such a method regarding bypass as numerous defense track designs as possible (by making them appear benign). At the very same time, the customized files were evaluated by the sandbox contest system. The files were to act precisely the exact same method as the initial destructive things.
In the attack competitors there was an API enabling us to get design forecasts (0 for tidy files, 1 for harmful ones). It was likewise possible to send out apply for a total test that consisted of not just a design category check, however likewise a sandbox habits contrast versus the originals.
.Dataset.
The organizers did not publish a dataset for the training designs (which may have worked in both the protective and assaulting parts for structure and try out designs). They recommended utilizing the Ember dataset , which has about 200,000 pre-calculated function vectors for identified malware and tidy files (100,000 for each class), as well as a big number of unlabeled vectors. The dataset uses rather an effective set of functions, consisting of byte circulation pie charts in the file and entropy, header indications, file areas, info about the file’s legible strings, and more.
.Experiments.
The contest subject highly overlapped with our current short article about attacks on ML designs. We chose to use the methods talked about in the post. We trained a neural network design on the Ember dataset utilizing its labeled part (presuming that the protectors would do the exact same). For each target destructive file, we started to iteratively alter specific functions (particularly, the byte pie charts and the string functions) utilizing gradient actions, therefore reducing the possibility of “bad” label forecast by the design. After numerous actions, a brand-new set of functions was acquired. Next we needed to develop a customized file that would have such functions. The customized file might be built either by including brand-new bytes to the end of the file (increasing the overlay) or by including several areas to the end of the file (prior to the overlay).
Note that this file adjustment technique considerably lowered the possibility of files getting categorized as malware —– not just for the assaulted neural network, however likewise for other totally various architecture designs we trained on the exact same dataset. The very first outcomes of the regional screening experiments were rather outstanding.
Yet 5 out of 6 contest designs continued spotting those customized files, similar to the originals. The only “tricked” design, as it ended up later on, was just regrettable at identifying destructive files and quickly puzzled by nearly any adjustment of the initial. There were 2 possibilities: either the getting involved designs need to utilize none of the functions we altered for the attack at all, or heuristics ought to be utilized in these designs to reduce the effects of the result of the modifications. The standard heuristic proposed by the organizers was to cut off the file’s last areas: this method the included areas result would be just disregarded.
.What functions are very important for the contest designs?
Our additional actions:
We looked for out what functions was essential for the classifiers. To do this we trained an improving design on the proposed dataset. We continued to determine the value of specific functions for target harmful files utilizing Shapley vectors. The photo listed below programs the functions impacting the category results one of the most. The color represents the function worth, and the position on the X axis reveals whether this worth presses the file into the “tidy” or the “malware” zone.
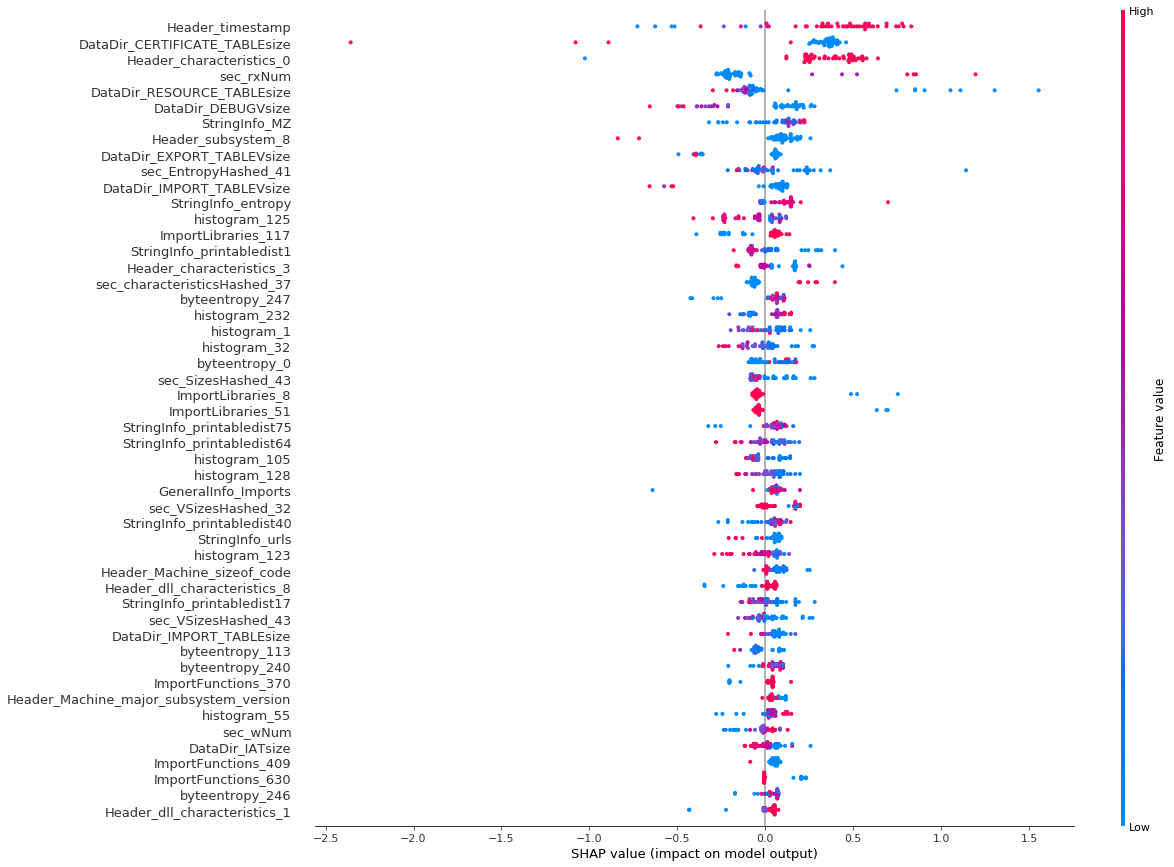
Feature value for file category
For example, the timestamp function has a considerable influence on the classifier. The smaller sized its worth (e.g., older file), the more the file is thought about to be “tidy”.
From the greatest effect functions we picked those that can be altered without breaking the executable file. We presumed that the participants’ designs ought to act likewise to our improving design, for they depended upon the exact same functions.
During our design research study, we discovered that the header, import table, directory site table functions are in some cases more crucial than the file areas information. If you take a tidy file, eliminate all areas and change them with areas from the malware file, 3 out of 6 designs will still consider it “tidy”. We likewise discovered that a person of the designs utilized heuristics to cut off the last areas. If malware areas were contributed to completion of a tidy file, the design’s decision would be “tidy”, however if placed prior to the tidy ones, the decision would alter to “malware”. We discovered the functions assisted to dependably bypass the 4 designs pointed out. And for the other 2, we discovered no constant technique to produce adversarial files (even not-working ones).
To totally alter the area includes with only small file adjustment, we found this intriguing faster way. To determine the function vector, the developers of the Ember dataset utilized the FeatureHasher class from the sklearn.feature _ extraction library . This class turns series of sets (function name, function worth) into a variety of repaired length. It specifies the position and indication (the indication will be essential even more on) by the hash of the function name. FeatureHasher deducts or includes (according to the indication) the matching function worth from the range position. The name of the area is utilized as the secret for such hashing, and the worth is figured out by its size and entropy. Hence, for any offered area you can contribute to the file another one with a specifically built name, so the functions of the brand-new one will fall under the exact same cell of the hash table —– however with opposite indications. Taking this concept even more, you might zero out all the worths in the hash table or construct any other worths by including an area of preferred name and size to the end.
.About the quality of the assaulted designs.
We attempted feeding numerous genuine applications to the entrants’ designs, such as Notepad, Paint, 7Zip, Putty, and so on, consisting of numerous Windows system executables. To our surprise, the designs would extremely frequently acknowledge them as harmful. The SECRET design , which took very first location in the protective part of the contest, discovered many of the tidy files we fed to it. Other designs, too, kept discovering tidy applications.
It may be improperly presumed that to win the competitors the very best defense method would be to acknowledge all files as destructive, other than those that are “tidy” in the training dataset. In truth such designs do not work. Due to the fact that the covert test dataset is not representative sufficient to evaluate the quality of the excellent designs, we believe this is. We even more think that the very same Ember dataset was most likely utilized by both the participants and the organizers, so the designs overfitted it. In the next versions of the contest we would recommend broadening the test dataset for the protective part of the contest with more tidy files.
.Last algorithm.
As an outcome of our analysis, the following last algorithm was constructed for how to customize the target harmful files:
.Take a tidy file not discovered by any contending design. In this case, we picked the system file setupcl.exe (bear in mind that non-system tidy files were typically discovered by some designs).Partly change the harmful file’s header to make it appear like that of a tidy file (however the file itself need to stay practical at the very same time).Utilizing the explained area hash technique, no out the “malware” area functions, then include areas from the pertinent tidy file to the end of the file to include those “tidy” functions.Make modifications to the directory site table, so it looks more like a tidy file’s table. This operation is the riskiest one, because the directory site table consists of the addresses and virtual sizes, the adjustment of which can make the file unusable.Change the fixed imports with vibrant ones (as an outcome, the import table turns empty, making it possible to deceive designs).
After these adjustments (without examining the file habits in the sandbox) we currently had ~ 180 competitors points —– enough for 2nd location. As you will find out later on, we did not handle to customize all the files properly.
.Outcomes.
Some adjustment operations are rather dangerous in regards to preserving appropriate file habits (particularly those with headers, directory site tables and imports). There were technical problems on the contest screening system side, so we had to evaluate the customized files in your area. Our test system had some distinctions, as an outcome, a few of the customized files stopped working to pass the contest sandbox. As an outcome, we scored little and took just 6th location in general.
.Conclusion.
As anti-phishing professionals, we had the ability to deduce, a minimum of in basic, how the designs worked by observing their outputs and develop an obfuscation plan to trick them. This demonstrates how difficult the job of identifying phishing pages really is, and why real-life production systems do not count on HTML code alone to obstruct them.
For us as malware professionals, it was fascinating to dive into some information of the structure of PE files and develop our own methods to trick anti-malware designs. This experience will assist us to enhance our own designs, making them less susceptible to adversarial attacks. It is worth discussing that in spite of the number of advanced scholastic ML-adversarial strategies nowadays, the basic heuristic method of customizing destructive items was the winning technique in the contest. We attempted a few of the adversarial ML strategies, however simple attacks needing no understanding of the design architecture or training dataset were still reliable in most cases.
Overall, it was an amazing competitors, and we wish to thank the organizers for the chance to hope and take part to see MLSEC establish even more, both technically and ideologically.
.
Read more: securelist.com